-
 重庆沙坪坝区融汇温泉城童话里D区5栋1905
重庆沙坪坝区融汇温泉城童话里D区5栋1905
-
 cqzhongrui160322@163.com
cqzhongrui160322@163.com
-
 王总: 13708368233
王总: 13708368233


给水排水 |机器学习在水处理系统中的应用:给水篇
来源:www.cqzrhj.com 发布时间:2023年04月04日
智慧化是目前水务事业发展的重要方向,机器学习作为实现人工智能的主要方法,在水务智慧化中有巨大的应用前景。本文从饮用水处理系统、排水处理系统和新技术研发三个方面,对机器学习的应用进行总结与评述。本文为上篇,在饮用水处理体系方面,综述了机器学习在水质水量、药剂投加、氯消毒等方面的应用。
下篇将总结污水处理系统方面处理过程控制、能耗节约、工艺效率提高、膜污染控制、故障诊断等方面的机器学习方法;归纳新技术研发方面机器学习在污染物高效去除的吸附与氧化等技术中的创新研究。
返回列表
下篇将总结污水处理系统方面处理过程控制、能耗节约、工艺效率提高、膜污染控制、故障诊断等方面的机器学习方法;归纳新技术研发方面机器学习在污染物高效去除的吸附与氧化等技术中的创新研究。
引用本文:皇甫小留,王晶瑞,龙鑫隆,等. 机器学习在水处理系统中的应用[J]. 给水排水,2022,48(11):153-165.
通信作者
皇甫小留
博士,教授。主要研究方向是智慧水环境科学,水环境铊污染防控。
人工智能作为21世纪尖 端技术的代表,是利用机器模拟人类的学习、思考、分析、决策等方式的技术,是实现智慧水务的重要手段。智慧水务作为现代水务发展的新趋势,是指利用物联网、大数据、云计算、人工智能等新信息技术,将水务系统状态信息传感技术、网络与移动系统相结合,构建集感知、仿真、诊断、预警、调度、控制和服务于一体的全 方 位智能化水务管理系统;涉及领域涵盖了水源调度、给排水处理系统、市政管网、海绵城市建设与管理、智慧客服以及综合性管控平台等。
随着用水量与污水量的持续增加,水处理技术的发展和处理规模的增大,处理工艺愈加复杂;另外,由于环境污染的严重性,水质、处理成本和处理效率的要求被提高。由于水务系统控制与管理拥有大量的数据,这些数据蕴含着各种反应机理和控制要素,各参数间存在非常复杂的非线性关系,其中包含的物理、化学和生物原理尚未研究透彻,因此传统自动控制过程只能给予一定的适度结果。基于一般规律的模型难以建立,只能依据经验进行调整,但这种模型的精度有限,过于依赖人力。因此迫切需要一种新的适用于解决非线性问题的自动化控制方法,充分利用水处理行业的数据信息,摆脱经验操作,实现自主学习控制。
机器学习通过分析归纳得出数据趋势,而不是基于编程的因果逻辑,因此机器学习只需要输入海 量数据,就可以自主构建数据间的关系,建立某种模型,进而根据模型对新数据进行判断和预测。另外,基于机器学习的模型虽然有一定的“黑箱”性,但可以通过适当的分析方法如Shapley值(SHAP)挖掘其深层的物理化学信息,因此机器学习具备一定的可解释性。机器学习依据其强大的学习和计算能力,可以在短时间内快速地处理海 量数据,非常适合处理非线性问题,如解释污染物的迁移与转换、分析和预测水质、揭露处理反应机理等。因此机器学习是智慧水务的重要实现途径之一,是水务智慧化的核心和关键。机器学习在水务上的应用有望对水务事业做出巨大的贡献,并推动水务事业从人工控制中解放出来,实现智慧控制。
据统计,已经有机器学习在自然和工程水体的应用综述、机器学习在污水处理技术和饮用水处理系统非线性问题分析中的应用汇总,但关于不同机器学习算法在水处理系统中的实际应用及对比性总结还没有研究。为增强业内人士对机器学习和智慧水务的认识,推动智慧水务进一步发展,本文综述了国内外机器学习在水处理系统和污染物去除新技术研发中的应用,包括水量预测、混凝分析、消毒模拟、过程控制、能耗节约、膜污染预警、故障诊断等;最 后讨论了代表性机器学习算法的优缺点和适用性;并分析了机器学习在水处理系统中应用的挑战和前景。
机器学习简述
在具有海 量性、高速性、多样性和失真性等特征的大数据时代,机器学习凭借其算法的低成本性、精 准预测性、机器自动化性受到各行各业的青睐。在水务信息化的进程中引入人工智能技术是发展的必然,这也将为水务智慧化、信息化带来新的机遇。
人工智能是在一个机器内嵌入相关算法后,多种算法相互结合,使机器拥有类似于人的行为,如观察、思考、学习、创造等;机器学习是人工智能的一个核心分支,旨在使计算机无需进行显示编程即可学习;深度学习是机器学习的子集,是一种含多隐藏层的深度神经网络结构。机器学习应用广泛,可以与各领域技术相结合,从而形成多种交叉学科,如模式识别、计算机视觉、语音识别、自然语言处理等。
机器学习可以分为监督学习、无监督学习和强化学习三个主要类别。监督学习包括分类和回归两种算法,基于输入和输出训练数据进行算法构建,可用于预测新输入数据所对应的输出。当输出只能取一个有限值集时,用分类算法;当输出可取一定范围内的任意数值时,用回归算法。无监督学习只能识别训练数据的共性特征,即在输入数据中寻找结构,并对新数据所呈现或缺失的共性特征作出判断,如聚类分析。强化学习是研究算法如何在动态环境中执行任务以实现累计奖励的最 大化,如博弈论、遗传算法等,见图1。
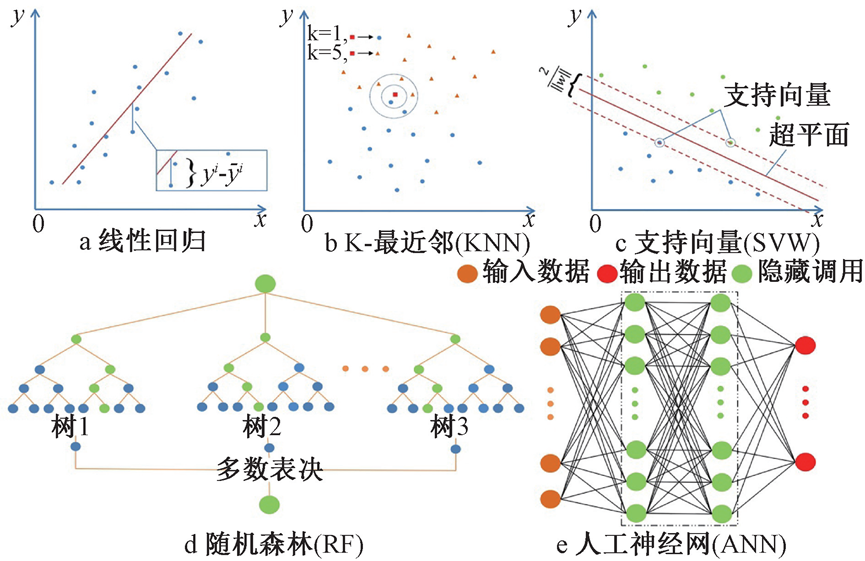
图1 本论文中回顾的常用算法原理
为训练机器学习模型,一般将数据分为训练集、测试集和验证集三个部分。首先,基于已选机器学习算法利用训练集对模型进行训练;其次,利用验证集数据通过调整超参数的方式优化训练后的模型;最 后,将测试集输入训练好的模型中,比较预测输出与其相应的已知结果,以评估训练模型的预测能力和泛化能力。相关系数(Pearson correlation coefficient,R2)、平均绝 对百分比误差(Mean absolute percentage error, MAPE)、平均绝 对误差(Mean absolute error, MAE)、均方根误差(Root mean square error, RMSE)、相对标准偏差(Relative standard deviation, RSD)、性能效率、精度等参数可用于评价模型准确性。常见的机器学习方法包括随机森林、支持向量机、人工神经网络、深度学习、模糊控制等。每种算法都依据其机理的不同,各有长处,应用场合也千差万别。不同算法之间也可以相互结合,取长补短,提高精度。单独算法往往存在一定缺陷,因此在复杂的水务工作中,通常将多种算法相互结合,共同控制。
机器学习在饮用水处理系统中的应用
饮用水厂作为保障居民生活的重要组成部分,传统自动控制系统主要依靠传感器监测数据,依据经验进行调整,具有实时性大、风险高、任务量重、控制复杂、精度有限、成本高等特点。将机器学习应用于水处理系统,将改变这一现状,实现基于大数据的过程控制和决策。以下综述了机器学习在需水量预测、药剂投加、氯消毒等方面的运用,包括水源水污染物监测识别、混凝用量的准确高效预测、消毒副产物的形成分析、膜污染的先进控制。
2.1 水量水质
需水量的预测是进行城市规划建设所必须的内容,用机器学习的方法精 确预测城市需水量是保证供水系统安全运行和实现科学管理与优化调度的有效手段。传统短期蓄水量预测一般采用回归分析方法,金冬梅等采用多元线性回归模型(Multivariable linear regress modal, MLR)以近年长春市用水量、人均收入及人口资料为输入参数,成功对长春市未来多年用水量进行预测。YASAR等以月平均水费、总人口数、大气温度、相对湿度、降雨量等为影响因素,采用逐步线性回归模型预测土耳其亚达纳的供水量。回归分析方法计算简单,对历史数据质量和影响参数的准确性有较高要求,适用于数据波动小的年用水量等问题,不适用于城市时需水量等数据波动大的问题预测。基于线型数据模型的自回归移动平均模型(Autoregressive integrated moving average mode, ARIMA)具有收敛速度快和鲁棒性等优点,在数据波动较大的日需水量预测中可取得较好的预测效果,但不适用于非线性时间序列问题。随着机器学习算法的进步,新的机器学习算法诞生,弥补了传统算法的缺点,提高了预测精度。人工神经网络(Artificial neural network, ANN)模型依据若干神经元节点及连接权重实现自主记忆,进而完成输入与输出变量的非线性映射。BENNETT等利用两个前馈反向传播、一个径向基函数网络等三种神经网络模型对建筑用水终端组件(淋浴、洗衣机等)需水量进行预测,并应用至全市用水量预测。舒媛媛等基于主成分分析(Principal component analysis, PCA)的反向传播神经网络(Back propagation neural network, BPNN)确定了人均收入、降雨量、居民生活用水量及生态环境用水量四个城市需水量影响因子,并对延安市年需水量进行了预测。ANN虽然很适用于大部分非线性时间序列的需水量,但该方法也存在训练时间长、易陷入局部最 优、训练数据量大等缺点。多种算法结合,能有效的提高单一模型的预测精度。BRENTAN等基于支持向量回归(Support vector regression, SVR)模型,结合自适应傅立叶级数预测偏差,利用巴西弗朗卡自来水公司需求数据对模型进行验证,效果较好。蒋白懿等利用一种灰色遗传(Genetic algorithm, GA)神经网络组合模型对某市区年居民生活年需水量进行预测,组合模型的预测结果与实际值相对误差仅为1.17%,相比灰色神经网络模型精度提高0.84%,比灰色遗传算法模型提高了3.08%。叶强强等利用混沌算法优化搜索BPNN模型的城市短期需水量预测全局最 优解,该模型容易确定输入层节点个数,具有收敛速度快,训练样本少等优点。极限学习机(Extreme learning machine, ELM)具有高稳定性和能力,被应用于预测短期需水量预测。与修正偏差的傅立叶级数模型结合,效果与ANN模型相当,但建模时间仅为后者的5%。
2.2 混凝沉淀
作为提高水质处理效率的水处理技术,混凝技术具有既经济又简便的优点,其关键问题是基于进水浊度对加药量进行预测,在保证出水水质的前提下精 准投加混凝剂是获得较好混凝效果及经济效益的前提。作为多输入单输出的非线性问题,模型的适用性对预测效果有重要影响。ANN模型依据简单的结构和鲁棒性被广泛应用于建立混凝模型。基于季节性原水变化和化学剂量,ANN模型被用于提高埃尔金地区污水处理厂过滤效率,该模型以0.63~0.79的相关性系数成功预测沉降水浊度,BPNN以0.78~0.89的相关系数计算出最 佳的混凝剂用量。为提高ANN的预测精度,可以与径向基函数神经(Radial basis function neural network, RBFNN)和广义回归神经网络(General regression neural network, GRNN)等其他算法联合,来模拟混凝过程,GRNN在数据量有限的情况下具有更好的性能,而多层感知器(Multilayer perceptron, MLP)更适合于全规模水厂数据及高浊度的水混凝问题。以原水流量、pH、进出水浊度以及对应的混凝剂用量为指标,选用GA优化BPNN中的连接权值和阈值,构建了基于GA和BPNN的微涡流混凝投药控制模型,也取得较好的预测效果。相对与其他智能控制算法,小脑神经网络算法具有逼近复杂函数、泛化能力强、收敛速度快等方面的优点。该模型可根据关联模糊隶属函数将多输入(原水温度、浊度、pH)-单输出(混凝剂用量)问题转化为多个关联的单输入-单输出的问题,因此结果准确率更高,控制更合理。另外,ELM与RBFNN结合的算法ELMRBF可显著降低计算量,在预测低浓度混凝剂用量中,模型相关系数超过0.97,高浓度模型中相关系数在0.80以上。田村山净水厂以进出水pH、温度、流量、浊度、每日混凝剂投加量均值、每3 h混凝剂投加量均值为特征参数,用长短时记忆网络(Long short term memory, LSTM)、极端梯度增强集成方法(Extreme Gradient Boosting, XGBoost)和随机森林(Random forest, RF)三种算法对单种或两种混凝剂投加量进行预测,最终采用了计算简单、精度更高的基于XGBoost算法的混凝投药模型。
2.3 氯消毒
氯是饮用水水厂主要的消毒剂,在消毒过程中,即要保证消毒效果,又要考虑副产物与气味问题。水体中的余氯变化是一个非线性时变过程,利用单纯神经网络模型虽然可以构建出余氯预测模型,但由于神经网络搜索速度慢、易陷入局部最 优、不适用于时变问题等缺点,其模型精度需要进一步提高。为搭建更加准确、稳定的水质余氯预测模型,安小宇等将正余弦算法(Sine Cosine Algorithm, SCA)用于改进BP神经网络的非线性权重,构建了SCA-BP水体余氯预测模型,该模型相对误差的平均值为4.04%,预测效果优于BPNN、RBFNN模型。另外,基于粒子群算法改进网络权值和阈值的PSO-BPNN模型也被应用在水厂消毒智能预测中,相对于传统 BPNN模型,该模型MAPE下降了1.8%,RSD下降了2.4%,并有效降低了氯消毒剂的使用量。针对小样本、高维空间问题,何自立等利用二阶振荡粒子群优化算法(Second-order Oscillation Particle Swarm Optimization, SOPSO)优化了SVR模型动态搜索最 优解的性能。另外,多种消毒剂分次投加的协同消毒具有非线性、不确定因素多、过程复杂等特点,相比于仅有反馈信号调节的统计控制,反馈与前馈信号相结合的智慧控制提高了消毒剂控制指标精度、减少了消毒投加量,并降低了消毒副产物的生成量。
除余氯预测外,消毒副产物(Disinfection by products, DBPs)也是氯消毒需要考虑的重要部分。在消毒过程中,以三氯甲烷(Trichlormethane, THM)和卤乙酸(Haloacetic acid, HAAs)为主体的DBPs与其前体存在高度非线性关系,传统预测模型无法模拟,机器学习技术无疑是深入了解该复杂关系的实用工具,且测定DBPs是一项非常繁琐、耗时、高成本的工作,通过机器学习算法准确预测其含量将对相关研究提供巨大便利。江钆泓等以南方某市7个自来水厂为研究对象,利用线性回归模型拟合进出水水质参数与两种主要消毒副产物生成量之间的关系,为消毒副产物的预测提供新的思路。PLATIKANOV等也利用线性回归如MLR和偏最 小二乘回归(Partial least squares regression, PLSR)成功确定了THM的形成条件及浓度。在进一步的研究中,利用非线性SVM和核PLSR证实了多操作变量之间的相互作用,核变换在说明变量之间的相关程度起到重要作用。由于DBPs的形成过程非常复杂,线性回归等算法不再适合,需要使用ANN、SVM等适用于非线性问题的算法。此类算法虽然具有一定的“黑箱”性质,但与其他算法如PCA或灵敏度分析等方式结合,可以加强对模型结果的解释性,提高模型的泛化能力和精度。KULKARNI等使用ANN来定量分析常规处理、氯化、颗粒活性炭处理和纳滤后的DBPs,并利用PCA评估了原水水质对三种DBPs前体去除效果的关系,减少了自变量个数,缩减了计算量。ANN可以准确地预测THM、HAAs和总有机卤素的浓度,预测的相关系数在0.92~0.97。SINGH等基于ANN、SVM和基因表达编程等算法建立模型,降低了模型误差,优化了自变量取值,基于有限数据集训练模型,以预测THM的形成。最终确定初始pH、接触时间和温度等三个参数为最 重 要影响因素,该模型在解决非线性问题方面具有更好的准确性和泛化能力。
消毒后水体的气味问题也值得被关注。MAO等将EPANET软件与BPNN模型结合起来,模拟饮用水分配系统中氯、氯胺和氯气味的强度。以控制水体嗅觉和最 小化投资为目的,该模型使得初始氯用量减少了50%,余氯合格率达到97.2%。
微信对原文有修改。原文标题:机器学习在水处理系统中的应用;作者:皇甫小留、王晶瑞、龙鑫隆、黄瑞星;作者单位:重庆大学环境与生态学院 三峡库区环境教育部重点实验室、哈尔滨工业大学环境学院 城市水资源与水环境国家重点实验室。刊登在《给水排水》2022年第 11期。


版权声明:本网站所刊内容未经本网站及作者本人许可,不得下载、转载或建立镜像等,违者本网站将追究其法律责任。 本网站所用文字图片部分来源于公共网络或者素材网站,凡图文未署名者均为原始状况,但作者发现后可告知认领, 我们仍会及时署名或依照作者本人意愿处理,如未及时联系本站,本网站不承担任何责任。备案号:渝ICP备2021002381号-1
 渝公网安备 50010602503057号
渝公网安备 50010602503057号