-
 重庆沙坪坝区融汇温泉城童话里D区5栋1905
重庆沙坪坝区融汇温泉城童话里D区5栋1905
-
 cqzhongrui160322@163.com
cqzhongrui160322@163.com
-
 王总: 13708368233
王总: 13708368233


给水排水 |机器学习在水处理系统中的应用:污水篇
来源:www.cqzrhj.com 发布时间:2023年04月04日
智慧水务是目前水务事业发展的重要方向,机器学习作为实现人工智能的主要方法,在水务智慧化中有巨大的应用前景。本文从饮用水处理系统、排水处理系统和新技术研发三个方面,对机器学习的应用进行总结与评述。本文为下篇,将总结污水处理系统方面处理过程控制、能耗节约、工艺效率提高、膜污染控制、故障诊断等方面的机器学习方法;归纳新技术研发方面机器学习在污染物高效去除的吸附与氧化等技术中的创新研究。最 后,系统分析了不同模型的优缺点与使用范围,对智慧水务中机器学习模型的选择和应用有一定的指导意义。
上篇综述了饮用水处理体系方面机器学习在水质水量、药剂投加、氯消毒等方面的应用。
引用本文:皇甫小留,王晶瑞,龙鑫隆,等. 机器学习在水处理系统中的应用[J]. 给水排水,2022,48(11):153-165.
通信作者
皇甫小留
博士,教授。主要研究方向是智慧水环境科学,水环境铊污染防控。
机器学习在污水处理系统中的应用
污水处理厂对降低水体污染物水平和提高水环境质量有重要意义。由于进出水水质、水量、各种污染物浓度、处理工艺等的差异,污水处理过程中包含了复杂的时变物理化学生物反应,因此污水处理过程控制要求操作人员具有丰富操作经验,能够及时发现数据异常。愈加严格的污水处理排放标准促使污水处理技术和整体管理更加精 准化和智能化,机器学习的应用可能有助于解决这一难题。本文总结了机器学习在污水处理工艺中处理过程控制、能耗节约、工艺效率提高和膜污染控制等方面的应用。
3.1 处理过程控制
污水处理的目的是去除污水中有机物、重金属、氮磷等污染物,处理效果主要根据化学需氧量(COD)、生化需氧量(BOD5)、总氮(TN)等参数间接评估。若能提前预知出水水质参数,及时调整处理过程,便能取得最 好的处理效果。然而在实际处理中这些参数的监测存在时滞性,往往滞后于操作,因此引入具有预测性能的机器学习算法有助于优化污水处理的过程控制。PATTANAYAK等以超过16 000个数据样本对比了MLR、MLP、SVR、RF和K-最近邻(k-nearest neighbor, KNN)等模型对污水处理厂实时COD的预测能力,结果表明KNN模型响应时间短,准确性高,表现最 佳。考虑废水处理的非线性,LIU等引入时滞系数,结合ELM提出了一种动态核极值学习机,用于预测出水COD。与单一偏最 小二乘法、ELM、动态ELM和核ELM模型相比,该模型精度更高。MIAO等考虑不同处理工艺运行参数,对比了SVR、LSTM和门控循环单元神经网络等模型对污水处理厂COD去除效率的预测精度,结果表明门控循环单元神经网模型效果最 佳。针对高污染状况,XGBoost方法具有鲁棒性、建模非正态变量能力和缺失值快速估计能力,因此该模型适合高浓度废水参数评估问题。在保证精度的同时减少了RBF算法的节点,可以有效降低计算量,使模型更加紧凑;误差校正和二阶学习算法提高了模型的学习能力和泛化能力。相对于RBF、最 小资源分配网络和广义生长等模型,自适应任务导向径向基函数对出水BOD和TN的预测,表现出更高的精度。另外,也可以利用灰度相关优化后的可见-近红外光谱对污水水质进行定量估算。以上方法说明机器学习在预测单一水质参数方面具有较高的精 确度,但多种出水水质参数间存在一定联系,单独预测可能会忽略彼此间的联系,且每次仅预测一个参数对于整个污水处理体系参数预测来说无疑的耗时耗力,因此多输出参数预测模型被建立。基于MLP-ANN和RBF-ANN对SBR工艺进行模拟,研究进水水质参数与控制参数对低浓度总悬浮固体(Total suspended solids,TSS)、总磷(Total phosphorus,TP)、COD和NH4+-N的去除效率的影响。相对于ANN,自适应神经模糊推理系统克服了ANN模型易陷入局部最 优、受输入参数缺失影响较大等缺点,也可以根据约束函数等优化设计,因此其对SS、COD和pH的预测性能要高于ANN。
3.2 能耗节约
污水处理过程中需要进行长时间曝气、加药、水泵回流等操作,这些过程既影响出水水质,也会影响运行成本。在保证出水水质达标的前提下,尽可能降低水处理运行成本是机器学习在污水处理中的一个重要作用。生物过程中的随机扰动较多,运用比例积分微分控制器(Proportion integration differentiation, PID)和先进模糊控制可以更自然地将人为经验转化为机器操作,集合成熟的变频调控技术等实时跟踪负荷变化,实现曝气量的优化控制。针对污水处理厂化学除磷过程中加药量优化的问题,广州某污水处理厂结合模糊技术与常规PID控制算法建立复合控制器,并与前馈的智能控制策略联合使用,实现了流量的精 准控制,节约40%~50%的除磷药剂量。另外,回流泵能耗也是污水处理运行成本中重要的组成部分,以最 小化能耗和最 大化泵送废水流量为目标,基于泵的能耗组件及能耗模型,建立了双目标优化自适应神经网络模型,在保证性能的同时节约能耗。
3.3 工艺效率提高
污水处理过程中各环节间各自独立又相互关联,提高每个环节的处理效率是节约污水处理成本、优化污水处理技术效率、保证处理效果稳定的有效方法。将机器学习与控制系统相结合,利用机器学习的学习、识别、预测、模拟等能力,可以实现优化控制,提高运行效率。HOLENDA等针对复杂的污水处理过程,提出了基于溶解氧(DO)线性状态空间模型的DO预测控制器。将所设计的预测控制器应用于好氧处理过程和交替式活性污泥过程实际控制,利用仿真模型进行性能评估,并分析研究了不同控制器参数对于预测控制器性能的影响。BELCHIOR等为了实现对污水处理DO浓度的控制,建立自适应模糊控制模型,控制辅助控制器平滑切换监督与非监督控制模式。基于时间序列控制间歇式活性污泥法反应器(Sequencing batch reactor activated sludge process, SBR),通过由监测层、管理层和控制层组成的三层网络控制系统分析影响去除有机物及脱氮过程的因素,从而实现智能控制。LIU等提出的了串级控制系统,由预测控制模型和比例积分导数控制器分别控制出水中和缺氧池硝酸盐的浓度,进而保证出水质量。PIRES等提出了基于模糊逻辑规则的专家控制系统,监测并调控水流通道和回流管道流速,从而改变生物池中碳氮比例,最终将硝化效率和反硝化效率分别提高至50%和85%。综上所述,模糊算法可以将人为操作、经验等转化为机器语言,使设备实现自动化控制,因此在提高设备工作效率方面,模糊控制具有巨大优势。
3.4 膜污染控制
膜污染是造成膜使用寿命短、处理工艺成本高的主要因素,也是阻碍膜处理技术发展的重大障碍。利用机器学习方法分析膜污染的形成过程,探究膜污染的影响因素,有助于减缓膜污染速度,对膜的设计优化也有一定的指导作用。影响膜污染的因素众多,相互联系密切,这将导致输入变量矩阵结果复杂。因此先利用PCA算法与对输入因素进行分类,再将相关数据输入BPNN模型进行拟合,这样既提高模型的准确度,又降低了计算的复杂性。LI等也通过上述步骤,确定混合液悬浮固体浓度、阻力和跨膜压力三个指标作为影响MBR膜通量的主要因素,之后,对比BPNN、SVM和RF三种模型对膜污染进行预测。其中,RF对膜通量的预测效果最 好。针对膜材料对膜性能的影响问题,HONG等对膜材料的污染特性进行了研究,结果表明纤维素酯的污染率明显低于聚偏氟乙烯。ALHADIDI等研究表明疏水性膜比亲水性膜更容易被污染。遗传编程在预测膜污染率中也表现出较高的适用性,一个利用遗传编程的模型以操作条件(流量和固定时间)和水质条件(浊度、温度和pH)为输入参数,构建膜污染函数,对膜的性能进行准确评估。HAN等建立了基于已有知识的模糊广义模型,从人文范畴资料中提取先关知识,利用模糊模型弥补缺失数据集。通过模型的分类识别功能进行膜污染的早期预警,并为膜污染提供操作建议。WOO等根据跨膜压力和次氯酸钠剂量提取影响因素,利用机器学习建立维护预测系统。该系统对膜老化进行判断,解释污染过程中功能参数间关系,进而推测膜的寿命,并对膜更换时间和膜维护提出建议。
3.5 故障诊断
污水处理过程是一个复杂的整体,包含着多种复杂的生物化学反应,每一个环节的偏差都将间接影响出水水质,因此污水处理厂中安装着各种水质参数监测设备,实时监测各污水处理设施的水质参数。并根据这些数据判断是否出现故障,以及时处理。进水水质的不稳定性导致水质参数具有一定的波动性,需要工作人员有丰富的经验判断监测数值是否正常。近年来,机器学习逐渐被应用于污水处理过程中的故障诊断方面。故障共分为个别故障、上下文故障和集体故障。故障监测方法可分为三大类:统计方法、学习模型和时间序列模型。统计方法和学习模型方法可以精 准捕获个别故障和上下文故障,应用范围较广。但在集体故障的时间模式中,这两个方法往往无法取得满意的效果。因此,时间序列模型是捕获集体故障的最 优方式。
KAZEMI等利用PCA模型与统计控制图结合的方式对总挥发性脂肪酸含量进行了预测,又基于SVM、ELM和神经网络集成等算法对模型的精度和鲁棒性进行优化,进而准确判断厌氧消化过程中的故障。由于生物膜的形成会导致DO传感器的误差,SAMUELSSON等设计了一个由自动训练和自动调整组成故障检测应用的程序,判断故意扰动是否会被解释为生物膜形成的偏差,从而准确预测DO的波动。另外,结果还表明输入数据包含的信息比先进的算法更重要。快速重力过滤器是许多水处理系统中的最终颗粒屏障,UPTON等以0.1NTU浊度为分界线,利用回归树算法有效地对过滤性能的最 大风险相关条件进行了建模和分析。
污水处理系统误差往往具有时序性和非线性,历史数据和数据预处理对模型的建立和训练具有重要意义,否则会出现维度过高,计算过程复杂,预测效果差等后果,因此需要通过一定的方式进行降维,提高可视化程度。高斯模型可以基于历史数据对多模过程的模态进行分类,之后再通过t-分布对数据进行降维,或结合极大似然估计对数据进行插值,优化模拟过程,降低噪声。MAMANDIPOOR等引入了ARIMA和时滞神经网络等系列建模方法来捕获污水处理过程中的时间模式,准确率超过92%。
新技术研发
重金属和有机物是水体中的主要污染物,具有较强的环境持久性,经过食物链进入人体后,将对人体产生危害。在过去的几十年里,物理吸附法已经被广泛证明可以去除水环境中的重金属离子和有机物。然而,随着越来越多的新型化学物质的出现,传统批处理和柱试验无法及时提供新吸附剂与新化合物吸附数据,进而影响进一步的研究。另外,氧化动力学的试验测量非常复杂和昂贵,反应速率常数的计算涉及到势能面的精 确化学信息,计算量非常大,这些因素都制约了氧化试验的深入研究。因此,挖掘已有数据来构建广泛的预测模型,实现对吸附和氧化过程快速准确的预测。预测精度高的模型可以取代一些重复、冗余的试验,精度中等的模型也可用于快速估计吸附剂或氧化剂的用量,从而帮助吸附和氧化试验的设计。因此机器学习算法在吸附和氧化机理研究上的应用将为吸附剂和氧化剂研发带来新的机遇。
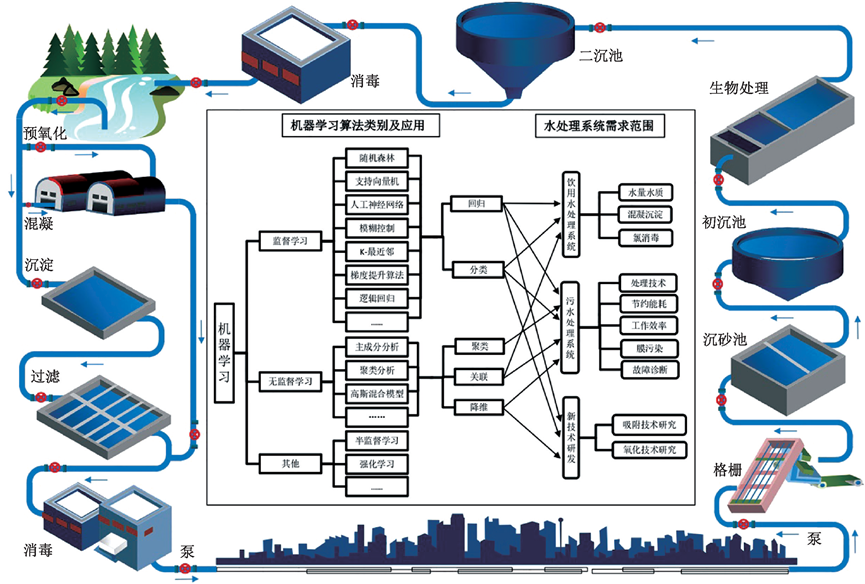
图2 机器学习算法的分类及其在水处理系统中的应用
4.1 吸附技术的研究
生物炭依据其低成本、高效性、无害性被广泛用于水处理中,生物炭吸附性能的研究也是所有吸附剂研究的重点。利用机器学习的方法探究生物炭与重金属、有机物的吸附影响因素对生物炭的改进研究和未来吸附实验的设计有指导性意义。
ZHAO等利用核极限学习机和克里金模型预测44种生物炭对重金属(Pb2+、Cd2+、Zn2+、Cu2+、Ni2+、As3+)的吸附效率,并通过点选择的方式提高模型精度,最 佳R2分别达0.919和0.980。逐步回归方法结果表明,溶液pH和温度是影响吸附过程的重要因素。另外,生物炭的阳离子交换能力和O/C等参数对吸附过程也有一定影响。ZHU等采用ANN和RF模型对6种重金属(铅、镉、镍、砷、铜、锌)对44个生物炭上的吸附进行建模。以生物炭特性、生物炭的初始浓度以及环境条件为控制参数,基于小样本数据对模型进行训练和优化。RF模型比ANN模型对吸附效率的预测具有更好的准确性和泛化性能,这可能与该模型训练数据较少、维度较高有关。以上研究开发的模型可以应用在经过特殊处理的生物炭选择问题上,影响参数的重要性分析可以为实际工程水体中重金属的高效去除提供参考。另外,在不同重金属吸附效率建模中,机器学习算法的精度受到吸附质-吸附剂和特定算法优缺点的限制。HAFSA等基于 RF、XGBoost和贝叶斯支持向量回归树,为多种重金属吸附剂的吸附效率建立一个广义预测模型,预测效果较佳(0.96≤R2≤0.99),并可以同时对多对重金属-吸附剂进行建模预测。
ZHANG等利用余弦相似的方式重点挖掘可用数据,将吸附系数与亚伯拉罕常数结合,建立利用神经网络-多元线性自由能的组合模型,预测有机污染物与吸附剂在不同平衡浓度下的吸附状况。该模型成功应用于各种平衡浓度吸附等温线模型,RMSE仅为0.23~0.31。然后,利用SHAP对模型性能进行分析。该模型采用多种数据处理和分析方法,对数据过滤、模型构建、模型参数化、模型训练等方面有一定的指导意义。
对吸附机理了解有限是限制纳米吸附材料在去除水中重金属的应用的重要因素,传统仪器和试验难以获得突破性成果。基于吸附动力学理论,利用机器学习方法探索纳米材料的微观结构,尝试恢复使用过的纳米材料,该方法对研制特定用途纳米材料和降低纳米材料制作成本提供了最新的思路。
4.2 氧化技术的研究
污水中的新型有机污染物越来越多,但大多数污水处理厂都不是为了处理这些新兴污染物而设计的,因此新的氧化技术已经被作为一种强大的有机物处理手段被应用于污水处理过程中。污染物的氧化速率常数是评估处理效果的重要参数,可以用来估计污染物的去除效率或确定氧化剂的剂量保留时间,因此利用机器学习模拟氧化过程,预测氧化速率常数,对氧化技术的改进和应用具有良好的辅助作用。SANCHES-NETO等利用XGBoost、RF、NN三种机器学习算法,结合摩根指纹和MACCS指纹,预测水相有机污染物自由基氧化过程的反应速率常数,R2均在0.9以上。SHAP方法被应用于特征重要性分析,辅助模型解释吸电子和供电子基团如何干扰OH·-和SO4·-自由基反应。另外,该研究还建立了通用的web程序界面,供以后氧化技术研究的应用与分析。
为研究HClO、O3、ClO2和SO4·-对有机物去除的影响,ZHONG等以氧化反应条件(pH和温度)为输入,结合小型的相似数据集建立了氧化预测模型。与图像处理技术对比,该模型预测效率更高,说明小型数据集间相似知识的迁移可以在一定程度上提高机器学习模型性能。CHA等基于荧光激发-发射矩阵数据,利用RF算法,以水质参数(pH、碱度、溶解有机碳浓度)为输入参数,模拟臭氧氧化污染物的过程。
污泥中存在不同的微生物、重金属、有机物和溶解盐等,因此在污水处理高标准的要求下,有效处理污泥中的污染物是实际工程中重要的环节。电氧化法是去除污水活性污泥中的有机化合物的新型技术,CURTEANU等利用ANN和SVR两种机器学习方法,研究了COD、电导率、溶解固体总量增加量、大肠杆菌状态等参数与有机物去除效率的关系,并利用仿真技术验证模型的可靠性。
多相催化氧化是新技术研究的热点,PALKOVITS等将ANN、SVR和KNN三种人工智能与电催化相结合,预测催化剂在水中多相催化氧化的效能,均取得较好的结果,其中,支持向量回归模型的性能最 好。
总结与展望
表1总结了不同机器学习算法的优缺点以及应用场所。不难得知,机器学习模型精度会受算法原理、原始数据集、问题的复杂性等因素影响,同种模型在不同场景下表现出的精度也不同。因此,针对不同的水处理问题,要充分考虑数据量大小、输入与输出参数关系、影响因素是否明确等多方面因素,进而进行模型的选择;另外,在模型建立过程中,针对算法本身缺陷,可以通过与其他算法结合,提高模型精度、缩短收敛时间、降低数据依赖。
总之,机器学习在水处理系统的应用仍处于初级阶段,为促进水务自动化和智能化发展进程,本文提出以下建议:
表1 机器学习算法的优缺点及其在水处理系统中的应用

(1)模型开发与组合。在水处理系统中没有一个完 美的模型可以适用于所有场所,不同的模型在不同条件下的表现也参差不齐。一般来说,组合模型比单一的模型效果更好。随着机器学习的发展,人工神经网络和深度神经网络的诞生使得传统模型不再需要编制内部计算过程,模型可以依据自身学习能力完成数据训练和预测。但这些方法需要大量的高质量的数据,因此数据的预处理尤为重要。开发新的预处理方式和学习模型将为水务事业带来新的前进空间。另外,现在的研究多针对单一处理环节,利用机器学习模拟处理过程,提高处理效率、节约能源等,对于整个水处理流程的统一模拟还没有相应的研究,对水处理系统进行整体评估的研究较少。
(2)建立数据共享平台。数据是机器学习在水务事业中应用的基础。无论是饮用水处理系统还是污水处理系统都需要大量的数据,但是数据集来源不确定、质量无法保证、输出格式各不相同,导致能被利用的数据数量大打折扣。因此,规范收集整理数据势在必行。另外,不同水务系统可以提供不同运行状态的数据,这样的数据更有利于模型训练。因此加强各个水务系统间的数据共享,将成为推动机器学习在水处理系统中进一步应用的强大动力。
(3)加强模型实践。大多数机器学习模型均处于研究阶段,在水处理系统中进行实际应用的研究较少,且现存水处理控制系统多仅使用简单模型。因此,应加强各类机器学习模型在实际水处理系统中的应用,获取运行数据,这将更有利于模型的开发和优化设计。
微信对原文有修改。原文标题:机器学习在水处理系统中的应用;作者:皇甫小留、王晶瑞、龙鑫隆、黄瑞星;作者单位:重庆大学环境与生态学院 三峡库区环境教育部重点实验室、哈尔滨工业大学环境学院 城市水资源与水环境国家重点实验室。刊登在《给水排水》2022年第 1 1期。


版权声明:本网站所刊内容未经本网站及作者本人许可,不得下载、转载或建立镜像等,违者本网站将追究其法律责任。 本网站所用文字图片部分来源于公共网络或者素材网站,凡图文未署名者均为原始状况,但作者发现后可告知认领, 我们仍会及时署名或依照作者本人意愿处理,如未及时联系本站,本网站不承担任何责任。备案号:渝ICP备2021002381号-1
 渝公网安备 50010602503057号
渝公网安备 50010602503057号